Create the Right Abstractions with DRY
DRY ("Do not Repeat Yourself") is a widely known best practice in software engineering, often understood as an imperative to de-duplicate identical chunks of code, boilerplate, or behaviors. Despite its popularity, there are opposing viewpoints. One counter-point I have often seen raised is a quote by Sandi Metz: "prefer duplication over the wrong abstraction". That post and this one at programmingisterrible.com describe how strict adherence to DRYing up code can lead to tight coupling, high complexity, high cognitive effort.
There are good points on both sides of the argument. On the one hand, duplicated code forces us to change multiple things. When I see duplicated code, I feel an irresistible compulsion to combine it in a new function or class. On the other hand, I hate tight coupling and complexity even more.
Can we deduplicate code without creating bad abstractions which make a codebase difficult to understand, maintain, and change?
Yes, DRY can help you design good abstractions. But this is the twist: I am not referring to the common understanding of DRY, but the original principle, which is concerned with collecting duplicate knowledge in a single place. This is not a matter of semantics -- it's a big distinction. It is another way of thinking about cohesion, which is a criteria for how to decompose a program into modules.
If your duplicated bits of code are related to the same idea, and if you can combine them within a well-designed module -- then you are well on your way towards a good abstraction.
The DRY Principle
The "DRY principle" -- was formulated in The Pragmatic Programmer by Andrew Hunt and David Thomas.
Every piece of knowledge must have a single, unambiguous, authoritative representation within a system (p 27, 1st ed)
There is nothing here about identical code or identical behaviors. Instead, we have the word "knowledge." Here's how they define it:
As programmers, we collect, organize, maintain, and harness knowledge. We document knowledge in specifications, we make it come alive in running code, and we use it to provide the checks needed during testing (p. 26, 1st ed)
Knowledge is an understanding of a business domain, or general problem domain. Domain knowledge relates to a set of real world problems in a given topic. It can be divided into subdomains. If we were building an HTTP client, we could divide subdomains around different general ideas: HTTP requests, responses, URLs, connection pools, SSL/TLS, and so forth. These ideas may be built over many more lower-level ideas: http verbs, headers, cookies, query params, status codes, certificates, protocols, etc. If we were building an e-commerce system, we would have domains around orders, inventory, a shopping cart, shipping, and so forth.
The DRY principle urges us to organize software such that all elements related to the same idea or sub-idea goes in its own safe place. This is another way of thinking about encapsulating stuff into a module, and hiding them behind a well-designed interface. It aligns with the conclusion of David Parnas's seminal paper "On the Criteria to be used in Decomposing Systems into Modules."
We propose instead that one begins with a list of difficult design decisions or design decisions which are likely to change. Each module is then designed to hide such a decision from the others.
The DRY principle is another way of thinking about cohesion. When stuff is related to the same idea, then that is a signal they could be combined because they will change for the same reasons at the same time. You can hide this cluster of cohesive sub-ideas from other parts of the system to minimize coupling. That coupling is when modules know too much about another, when the knowledge is duplicated. A well-designed module should offer a smaller simpler way to express the idea in shorthand: an abstraction.
"Being abstract is something profoundly different from being vague … The purpose of abstraction is not to be vague, but to create a new semantic level in which one can be absolutely precise." Edsger Dijkstra
Let's tighten up what I mean by "module." I'll define it as anything with a public interface which does some useful behavior. This applies to any scope or scale: a function, a class, a library, a language-specific module, a command-line program, a service API. A module is often composed of other lower-level modules. I wrote about this in another post.
Obviously modules on their own do not lead to good code. Parnas's paper is not about modules. It's about how you decompose the problem. The DRY principle is a framework of thought to help guide you in decomposing the problem into cohesive grouping of ideas. Then you only need to change stuff related to an idea in a single place. Most importantly, as long as you don't change the contract of your module's interface, then those changes won't impact the modules which depend on it.
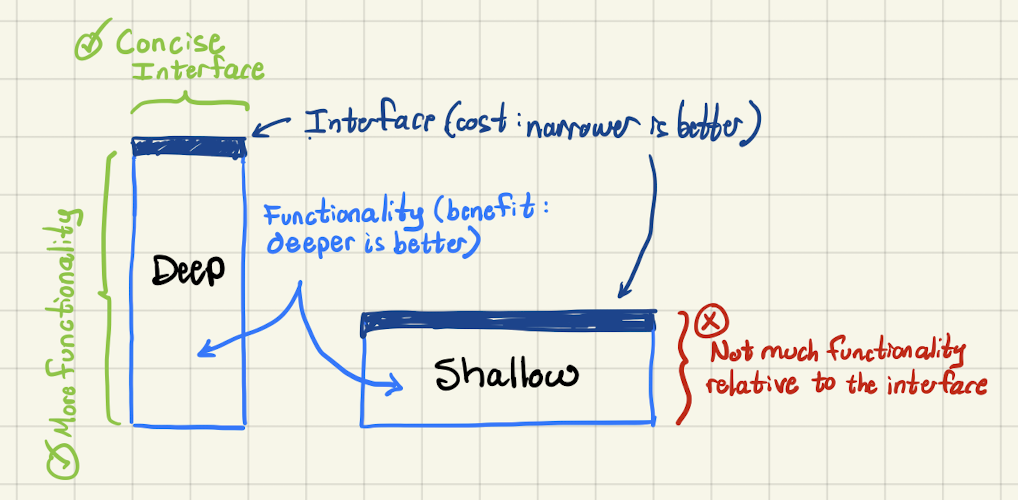
As far as the practical design of modules, I highly recommend reading "A Philosophy of Software Design" by John Ousterhout. One technique from that book is to build modules with the smallest external interface in relation to the depth of the features it provides.
The benefit provided by a module is its functionality. The cost of a module (in terms of system complexity) is its interface.
This is a powerful way to evaluate the cost/benefit of a module. How concisely does it abstract the knowledge within? How well does it protect itself from coupling? How well does it lend itself to general re-use?
There is one drawback here: this is not always easy. Designing good modules is often a hard task, and it may conflict against the pressure to deliver results in a limited amount of time. If that's the case, maybe consider the advice we're going to look into next.
The Wrong Abstraction
Sandi Metz offered an alternative perspective to DRY in the 2016 post The Wrong Abstraction. I often see it condensed to this single quote:
Duplication is far cheaper than the wrong abstraction
This point is directed towards the common understanding of DRY -- identical code, boilerplate, or behavior. We can see this when we analyze what "duplication" means in the context of the blog post. The post describes an example of two developers mangling an abstraction, which I except below:
Programmer A sees duplication. Programmer A extracts duplication and gives it a name.
A new requirement appears for which the current abstraction is almost perfect.
Programmer B feels honor-bound to retain the existing abstraction, but since isn't exactly the same for every case, they alter the code to take a parameter, and then add logic to conditionally do the right thing based on the value of that parameter.
What was once a universal abstraction now behaves differently for different cases.
Programmer B has a requirement that needs duplicate behavior that Programmer A's abstraction could almost provide. The example ends with other developers coming along and doing the same thing, over and over until ...
The code no longer represents a single, common abstraction, but has instead become a condition-laden procedure which interleaves a number of vaguely associated ideas. It is hard to understand and easy to break.
This example illustrates a truth: the pressure to avoid duplicate code is a trigger to create an abstraction. Avoiding duplicate code is used as a criteria for decomposition. And sometimes it's the only criteria!
But the compulsion to "DRY up" code is not the only problem the post illustrates. I see three other anti-patterns in the example.
- Changing the existing interface: This is a risky change that needs to be done with caution, or not at all. If the design of the existing interface is insufficient, then design a better interface (or live with the duplicated code). And don't modify the existing module; instead, implement a new one. Migrate other downstream dependencies later, in a dedicated commit.
- Little to no effort in the design of the interface: In the example, it is implied that neither developer spent much time designing the abstraction. As we have seen, every new module incurs a cost, and that cost is based on the quality of the interface. Without any design effort, it's more likely the cost will outweigh its benefit.
- Pushing details of a higher-level module into a lower-level module: The example developers are writing higher level business logic. They push pieces of that logic down into a lower-level abstraction, but without re-working those pieces into a generalized idea that fits the abstraction. This is evidenced by the use of parameter flags and conditions to change the modality of the abstraction's behavior to suit the specific needs.
The common thread in these anti-patterns are a poor discipline in decomposing the problem and designing good code. These are the cause of the bad abstraction -- not the urge to de-duplicate code. That urge is merely a trigger. If we avoid these anti-patterns, we are more likely to implement good abstractions in our code.
In the end, it's a matter of cost. The cost of an abstraction is incurred by interface. So duplicate code can be cheaper, but I have some caveats:
- It's only cheaper if each occurrence of the duplicate code is a hidden detail within some module.
- We should limit this to duplicate code that is not related to the same idea, or when it's not yet known if they are related; otherwise, we should design a module to encapsulate it.
The Problem with D.R.Y.
I see no problem with the DRY Principle, but I think there is a problem with D.R.Y., that clever little acronym.
An acronym is a mnemonic that acts as shorthand to the bigger idea it represents. But what if people only learn the shorthand, and fail to learn or understand the bigger idea? Or what if they forget the bigger idea? Or can only recall a superficial vestige of that idea? What if they learn a different idea altogether?
This post from programmingisterrible takes a few shots at DRY, and each one of them are solid points that I think relates to this misinterpretation.
“Don’t Repeat Yourself” is almost a truism—if anything, the point of programming is to avoid work.
I imagine there are engineers who cargo cult DRY and never get much further from the literal meaning derived from the acronym. The literal meaning is so obvious its not even worth saying.
“Don’t Repeat Yourself” often gets interpreted as “Don’t Copy Paste” or to avoid repeating code within the codebase
This point relates to Sandi Metz's blog post, which we have already covered. I have added emphasis to a phrase in this quote, because it highlights the nature of the problem I'm trying to expose. Interpreted. No one should need to interpret the DRY principle, because the original meaning is sufficient.
With “Don’t Repeat Yourself”, some insist that it isn’t about avoiding duplication of code, but about avoiding duplication of functionality or duplication of responsibility. This is more popularly known as the “Single Responsibility Principle”, and it’s just as easily mishandled.
I couldn't agree more.
But wait -- doesn't this point conflict against the core idea of this post that we use DRY to put code related to the same idea into a single module?
No, this quote is specifically calling out the Single Responsible Principle ("SRP").
A class should have one, and only one, reason to change.
The SRP is a failed attempt to summarize Parnas's criteria for decomposition. It tries to boil it down into a pithy sentence, but in doing so loses sight of the key concepts like cohesion, coupling, hiding complexity, collecting and hiding things that will change together. Like DRY, it is too easy to misinterpret and cargo-cult. The SRP adds a weird point that there should only be one reason to change, which is unclear, restrictive, and easy to misinterpret. The single responsible principle is a "bad abstraction".
Conclusion
I'm not trying to redefine how people think about DRY. I'm not trying to get us back to the beginning. The general understanding of DRY is probably so divorced from the original meaning that there's no point trying to re-map every software engineer's understanding of it.
What I want above all is to harness the power of well-designed abstractions, and I want to minimize duplicated code. For a while there, I thought the wisdom in some of those blogs posts I linked conflicted with what I wanted to achieve. Through the effort of writing this post, I have reconciled that wisdom against foundational principles of good software design. I hope this helps others as well.