Simplify Software with the Repository Pattern
Introduction
Write simple software to manage complexity. This is the primary technical imperative [McConnell].
In a previous post -- Make It Simple -- I landed on this conclusion:
To write simple software, understand the problem domain, decompose it down to a set of sub-problems, encapsulate them in independent modules, and then compose up the full solution out of those pieces.
Design patterns are pre-packaged modular compositions for commonly occurring problems. Even if you do not use a pattern, or like it, or agree with it, or find it solves the problem at all -- every pattern can be useful for learning the principles of encapsulation and composition. We all stand to benefit from kicking the tires. Recently, this blog post about the Repository Pattern had piqued my interest. The author does a great job explaining it, but then veers a tad too much towards a single benefit (swapping databases). I wrote this post to describe how it can simplify a critical part of your code.
Before we dive in, we're going to pull back and examine the problem itself: coupled domain and persistence logic. We'll look at an example of some bad code, a common alternative design pattern, and then I'll define my understanding of the Repository Pattern pattern, and refactor that bad code example.
Why Simplicity?
God, I hope I don't have to explain this. Just in case, I'll lay it out.
Simple software is not a "nice-to-have.". It adds tremendous value to the business [Fowler - 2019]. Let's summarize a few benefits (and the business value):
Simple code is ...
- ... easier to understand (feature velocity, fewer bugs)
- ... faster to extend (feature velocity, lower ops cost)
- ... easier to maintain in the long term (lower ops cost, feature velocity)
- ... easier to test (fewer bugs, safer code)
- ... easier to deploy (lower ops costs, feature velocity)
- ... more fun to work in (developer retention)
For software critical to the business or that must be supported for longer than a month, simplicity must be the top concern.
Software engineering is programming integrated over time ... we might need to delineate between programming tasks (development) and software engineering tasks (development, modification, maintenance). The addition of time adds an important new dimension to programming. Cubes aren't squares, distance isn't velocity. Software engineering isn't programming. [Winters, et al]
We must evaluate the quality of our code based on a projection of changes that are likely to occur in its lifetime. The longer a service lives (and profitable software tends to live a long time), the probability of a given change increases.
The Problem
There is a tendency for domain logic and persistence logic to become coupled.
By domain logic, I mean high level code that solves problems specific to your business and to your domain (I'm loosely relying on the definition from Domain Driven Design). This code is closer to the user stories and requirements defined by the business.
Persistence logic is lower level code that bridges your domain logic to the database technology of choice. It hides all the details on how to use the database to read and write data. It encapsulates its limitations and quirks. It hides complex optimizations you have built in. This code is less specific to your particular business problems; instead, it's more focused on technical problems. It is further away from the user stories, and is more concerned with crucial functional requirements like security, availability, durability, performance, etc.
Coupling is bad. If you use Rich Hickey's definitions for simplicity and complexity, then coupling is literally synonymous with complexity [Hickey]. It is not simple -- and it moves you further from the benefits outlined above.

Here's a picture of some code that has been lovingly coupled together into a big ball of *cough* mud
A Bad Example
For our domain, we'll use Wishlists -- exactly like those one might encounter on an eCommerce website. Users can create multiple Wishlists to add, sort, and organize products that they would like buy someday. For the demo, the Wishlist will have a minimum amount of data, but we will toss in a rule that when creating a Wishlist, the name should be unique for that given user.
The examples throughout this post are written in Java, and we'll use AWS DynamoDB as our database (with the SDK v2 enhanced client). You don't need to be familiar with it to follow along. Also, we will ignore the API layer (e.g. HTTP, REST, etc).
public class WishlistService {
private static final Logger log = LoggerFactory.getLogger(WishlistService.class);
// these static variables already hint at mixed concerns
private static final String TABLE_NAME = "202001020304_wishlist-table";
private static final int MAX_USERNAME_LENGTH = 64;
private static final Pattern USERNAME_REGEX = Pattern.compile("[A-Za-z0-9@.]+");
private final DynamoDbTable<Wishlist> wishlistDynamoDbTable;
public WishlistService(DynamoDbEnhancedClient dynamoDbEnhanced) {
wishlistDynamoDbTable = dynamoDbEnhanced.table(TABLE_NAME,
TableSchema.fromBean(Wishlist.class));
}
public void createWishlist(UUID ownerId, String wishlistName) {
// Initializing the Wishlist with data belongs to the domain logic
UUID newId = createWishlistId(ownerId, wishlistName);
Wishlist wishlist = Wishlist.builder()
.id(newId)
.ownerId(ownerId)
.name(wishlistName)
.createdAt(Instant.now())
.build();
// Validation: more domain logic
Optional<String> validationError = validate(wishlist);
if (validationError.isPresent()) {
throw new IllegalArgumentException("invalid create user request: "
+ validationError.get());
}
// Now we must mentally switch gears, and depend on our
// knowledge of Dynamo, and the enhanced client. We'll probably
// need to re-read some docs (I did!). I mean, who the heck
// is going to remember syntax for "attribute_not_exists(id)"?
try {
wishlistDynamoDbTable.putItem(PutItemEnhancedRequest
.builder(Wishlist.class)
.item(wishlist)
.conditionExpression(Expression.builder()
.expression("attribute_not_exists(id)")
.build())
.build());
} catch (ConditionalCheckFailedException e) {
throw new AlreadyExistsException(e);
} catch (SdkServiceException e) {
logger.error("exception while calling putItem on " +
"table={} for wishlist=[name={}, owner={}]",
wishlistStorableTable.tableName(),
wishlist.name(),
wishlist.ownerId(),
e);
throw new RuntimeException("internal service error");
}
}
private Optional<String> validate(Wishlist wishlist) {
String err = null;
if (wishlist.name().isBlank()) {
err = "invalid wishlist: the name cannot be blank";
} else if (wishlist.name().length() > MAX_USERNAME_LENGTH) {
err = "invalid wishlist: the name cannot exceed "
+ MAX_USERNAME_LENGTH + " characters";
} else if (!USERNAME_REGEX.matcher(wishlist.name()).matches()) {
err = "invalid wishlist: the name contains invalid characters";
}
return Optional.ofNullable(err);
}
// But wait ... we have more to do!
public Item addItemToWishlist(String wishlistId, String itemDetails) {
// TODO
}
public void deleteItem(String wishlistId, String itemId) {
// TODO
}
public void deleteWishlist(String wishlistId, String itemId) {
// TODO
}
public Wishlist getWishlistById(String wishlistId) {
// TODO
}
public List<Wishlist> listWishlistsByOwner(UUID ownerId) {
// TODO
}
public void reorderItemInWishlist(
String wishlistId,
String itemId,
int index
) {
// more code
}
/*
* Create uuid based on the ownerId and name
*/
private UUID createWishlistId(UUID ownerId, String name) {
String idInput = ownerId + ID_DELIMITER + name;
return UUID.nameUUIDFromBytes(idInput.getBytes());
}
}
// Here's our Wishlist data object, coupled to our database via
// annotations from the dynamodb-enhanced library
@DynamoDbBean
public class Wishlist {
private String id;
private String ownerId;
private String name;
private Instant createdAt;
public static class Builder() { ... }
@DynamoDbPartitionKey
public String getId() { ... }
// other getters and setters
}
This code mixes concerns. It is not doing one thing, and doing it well. As it changes over time, it will be harder to understand, harder to extend, and harder to maintain. Let's consider changes that are likely to occur in the lifetime of our service that would impact the domain and/or persistence logic.
-
Adding more features [will happen]
- Adds more code that interacts with the domain and persistence constructs.
- For instance, we could might start emitting notifications (e.g. emails, or event-driven architecture): this would introduce another distributed tool the
WishlistServicewould become coupled to (e.g. RabbitMQ, AWS SNS). - Interacting with another domain or tool (e.g. Auth): more coupling.
-
Updating the database [will happen]
- e.g. The database major version. There is not enough room here to describe the pain and anguish that was wrought upon a former team of mine by having the monolithic backend services coupled to MySQL 5.0
- Dynamo doesn't have versions ... but the AWS SDK does. Upgrading major versions requires a full re-write of client code.
-
Changing how we use the database [probably will happen]
- Changing query patterns or indices.
- Schema changes.
- Migrating to different tables / partitions.
- Performance tuning.
-
Adding a cache [might happen]
- More coupling: the code must manage interactions between the cache and the persistence layer.
-
Switching to a different database [probably not ... but never say never]
- For a well-designed service, there should be low risk of this happening (migrating your code will be hard, but migrating your data and live traffic will be even harder).
- Even for the best services, it can happen for unexpected reasons (your company decides it is too expensive to use database X, so services must migrate to approved databases Y or Z).
EXERCISE
As an exercise, try to re-write the example code above to make it use an in-memory cache. Copy/paste it into your IDE, and spend fifteen minutes drafting a solution. How does the code look now?
A Solution: Layered Architecture
Before introducing the star of the show, I want to address a well-known pattern often used to solve this problem: Layered Architecture [Wikipedia - MA]
N-tier application architecture provides a model by which developers can create flexible and reusable applications. By segregating an application into tiers, developers acquire the option of modifying or adding a specific layer, instead of reworking the entire application.
That's the dream, any way. For a vanilla web service using this architectural pattern, it's typical to use a three-tier architecture: controller, domain, and repository. Let's set aside the controller layer, and focus on the other two.
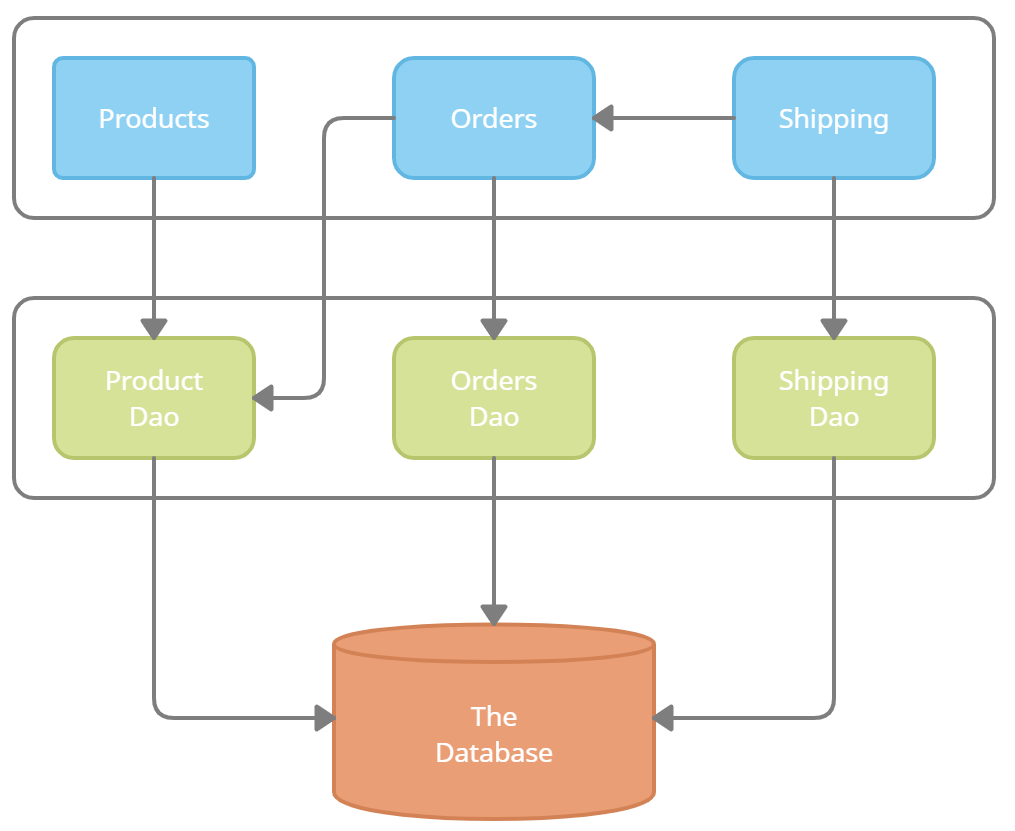
There are at least two disadvantages to Layered Architecture.
First, it does not include a concept for individual domains. For instance, in a monolithic service, there is no mechanism or convention in this pattern to prevent logic from coupling to other domains on the same level, or to dip into other levels.
Second, components in higher levels depend directly on dependencies in the lower level. In much of the code I have read, the higher level usually couples directly to concrete classes in the lower level. This can be improved slightly by having the lower level define interfaces -- but it does not address the overall cause of coupling. The interfaces of the lower level are driving behavior in the higher levels. If you change the lower, it will ripple up through the layers. When you make changes in the top layers, you must be aware of the nitty gritty details in the levels below.
If you have read David Parnas's paper on modularity (which I have summarized in another post), he expresses two general strategies for composing software: the flowchart (high coupling) and the acyclic graph of independent modules (low coupling) [Parnas]. Layered architecture is the flowchart style. It's literally modeled that way.
For even more on why layered architecture is not ideal, checkout "Levels of Modularity".
EXERCISE
Did you do that exercise from the previous section to add an in-memory cache? Okay, great! Now, change it to use Redis. What changes are you doing to need to make to your code? To your tests? To your dependencies?
An Improved Solution: The Repository Pattern
It's not a complicated pattern. Use dependency inversion so that both the domain and persistence components depend on the same interface. And this is key: the interface should be owned by the domain -- it should live in the same sub-module. The interface should be designed based on the needs of the domain. The persistence logic depends on this interface and any models it uses, and must adapt itself to its needs. The domain should not depend on anything defined in the persistence sub-module.
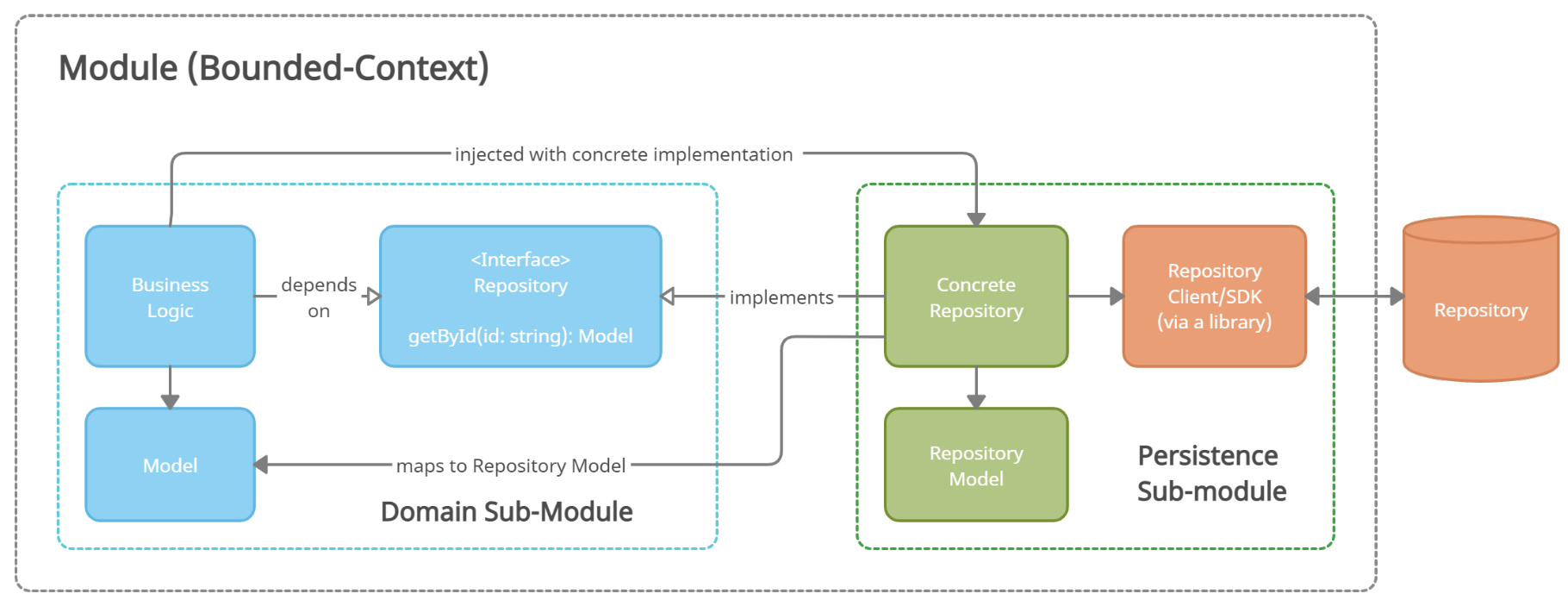
With this pattern, how you use and interact with your database is generally driven by your business needs -- not the other way around.
But only "generally." There will be some push and pull. For instance, to optimize cost or performance, you may have to hand over some chunk of responsibility from the domain to the persistence module. You may need to shape the interface -- and how the domain uses it -- based on how you plan to implement the schema and/or interactions with the database. That's probably okay. That's the art of design: managing trade-offs.
The most critical unbendable rule is that the domain code must not have a single dependency on the specific persistence technology. Then the code is agnostic, even if some of the behavior has been influenced by the specific database. But please minimize this as much as possible.
A Better Example
The directory (package) structure is important for figuring out where stuff goes, so let me map that out first:
src/
main/
java/
org.alexgraham.wishlist/
domain/
Repository.java
Wishlist.java
WishlistService.java
persistence/
DynamoRepository.java
WishlistStorable.java
Let's start with the wishlist.domain.Repository ... which is the critical piece after all. For our first feature, it is rather spare: a single method. Notice the interface also specifies expected behavior for error handling (implicitly, in comments, because in Java the only way to codify errors in an interface is with checked exceptions, which do not play nicely with Java 8 lambdas).
package org.alexgraham.wishlist.domain;
public interface Repository {
/**
* Saves a new Wishlist in persistence.
*
* @param wishlist The Wishlist to save.
* @throws AlreadyExistsException if the Wishlist with the given id already exists.
*/
void saveNew(Wishlist wishlist);
}
Let's look at what it is saving: the Wishlist itself. With this class, we avoid the anemic domain model anti-pattern [Fowler - 2003] by making it responsible for any domain logic related to Wishlist data. Notice those DynamoDB annotations are not here. Again, the domain should not have any direct or indirect dependency on the specific database.
package org.alexgraham.wishlist.domain;
public class Wishlist {
private final UUID id;
private final UUID ownerId;
private final String name;
private final Instant createdAt;
// private constructor
private Wishlist(UUID id, UUID ownerId, String name, Instant createdAt) { ... }
// Creates a new Wishlist.
public static Wishlist create(UUID ownerId, String name) {
UUID id = createId(ownerId, name);
return new Wishlist(id, ownerId, name, Instant.now());
}
// Re-creates a Wishlist from some raw data
public static Wishlist rehydrate(UUID wishlistId, UUID ownerId, String name) { ... }
// if invalid, returns reason in the Optional<String>
public Optional<String> validate() { ... }
// Creates a uuid based on the ownerId and name
private static UUID createId(UUID ownerId, String name) {
String idInput = ownerId + ID_DELIMITER + name;
return UUID.nameUUIDFromBytes(idInput.getBytes());
}
}
Moving on. The WishlistService contains our use case logic. It is responsible for taking one or more sub-modules, and composing them together to implement features. Right now, it uses two "sub-modules": the Wishlist and the Repository. Not even a whispered hint of Dynamo.
package org.alexgraham.wishlist.domain;
public class WishlistService {
private final Repository repo;
public WishlistService(Repository repo) { this.repo = repo; }
public Wishlist createWishlist(UUID ownerId, String name) {
Wishlist newWishlist = Wishlist.create(ownerId, name);
if (newWishlist.validate().isPresent()) {
throw new IllegalArgumentException("The wishlist arguments are invalid: " + newWishlist.validate().get());
}
try {
repo.save(newWishlist);
} catch (IllegalArgumentException e) {
throw new IllegalArgumentException(
"invalid request: wishlist with name={} already exists for owner={}",
newWishlist.getName(),
newWishlist.getOwner());
} catch (RuntimeException e) {
throw new RuntimeException("Internal Server Error");
}
return newWishlist;
}
}
Let's drill down and take a peak at the DynamoRepository. It does one thing, and does it well. Notice the error handling: it conforms to the behavior specified by the interface.
package org.alexgraham.wishlist.persistence;
import org.alexgraham.wishlist.domain.Repository;
import org.alexgraham.wishlist.domain.Wishlist;
public class DynamoRepository implements Repository {
private final DynamoDbTable<WishlistStorable> wishlistStorableTable;
public DynamoRepository(
DynamoDbEnhancedClient dynamoDbEnhanced,
String tableName
) {
this.wishlistStorableTable = dynamoDbEnhanced.table(
tableName,
TableSchema.fromBean(WishlistStorable.class)
);
}
@Override
public void save(Wishlist wishlist) {
try {
wishlistDynamoDbTable.putItem(PutItemEnhancedRequest.builder(Wishlist.class)
.item(wishlist)
.conditionExpression(Expression.builder()
.expression("attribute_not_exists(uniquenessKey)")
.build())
.build());
} catch (ConditionalCheckFailedException e) {
throw new IllegalArgumentException(e);
} catch (SdkServiceException e) {
log.error("unexpected dynamo exception while creating wishlist={}", wishlist, e);
throw new RuntimeException("Internal Server Error");
}
}
}
Yes, we have two different wishlist objects:
wishlist.domain.Wishlistwishlist.persistence.WishlistStorable
These objects have separate concerns. We have already covered responsibilities of the first. The WishlistStorable is responsible for modeling the schema of the data record we persist in Dynamo. It is responsible for adhering to implicit rules established by the DynamoDB Enhanced Client. Yes, there is some tedious mapping logic -- but that is a small price to pay for fully decoupling your modules!
package org.alexgraham.wishlist.persistence;
import org.alexgraham.wishlist.domain.Item;
import org.alexgraham.wishlist.domain.Wishlist;
@DynamoDbBean
public class WishlistStorable {
private String id;
private String ownerId;
private String name;
public WishlistStorable() {
// default empty constructor
}
public WishlistStorable(String id, String ownerId, String name) {
this.id = id;
this.ownerId = ownerId;
this.name = name;
}
static WishlistStorable fromWishlist(Wishlist wishlist) {
return new WishlistStorable(
wishlist.wishlistId().toString(),
wishlist.ownerId().toString(),
wishlist.name());
}
public Wishlist toWishlist() {
return Wishlist.rehydrate(
UUID.fromString(id),
UUID.fromString(ownerId),
name);
}
@DynamoDbPartitionKey
public String getId() {
return id;
}
// other getters and setters
}
And there we have it:
- The concerns of domain and persistence have been separated.
- We have independent modules that do one thing and do it well
- Each module is easier to understand and test.
Yes, we have more code and more classes. The goal of simplicity is not less code (although that will likely result as you build in more and more features). DRY != Simple.
More Code ...
Earlier in this post I stated the following:
We must evaluate the quality of our code based on a projection of changes that are likely to occur in its lifetime.
One example of a design pattern at one point in time can only demonstrate how to use the pattern -- it cannot validate whether or not it makes true on the promise to keep code simple over time.
So I continued adding features to this Wishlist demo, constantly evaluating whether or not the pattern maintained simplicity in the face of change and increasing complexity. You can see each change in the github repo:
Repository Pattern Demo Github Repo (the README summarizes each change).
In a three-month gap between drafts of this blog post, I used the pattern in a non-trivial personal project that I have been iteratively working on. As the code base continues to grow in size, as I add more complex features, my cognitive load has remained manageable, and my development velocity high.
Meanwhile at work, I have encountered multiple situations where this pattern would have saved a great deal of time, reduced pain, and reduced complexity. I plan to refactor production code to match this pattern, and reduce the cognitive load for myself and my team.
A General Pattern Emerges
If we zoom out, we realize "The Repository Pattern" as its defined in this post it is actually a compound pattern. It's simply the Adapter Pattern with a twist of Dependency Inversion:
- High-level modules should not depend on low-level modules. Both should depend on abstractions (e.g., interfaces).
- Abstractions should not depend on details. Details (concrete implementations) should depend on abstractions.
But here's the rub: the Abstraction (e.g. the Repository) that the the high and low level modules depend on is owned by the higher-level module (e.g the domain). In other words, the abstraction is written and shaped by the needs of the higher-level thing. Then, the Adapter we create (e.g. the DynamoRepository) and presumably load in with some kind of Dependency Injection, becomes a kind of plug-in. By the way, this is highly related to the idea behind Ports and Adapters design pattern [Cockburn].
Once we grasp the general pattern, we start to realize "Repository" is too specific and even unnecessary. We could apply this to any situation where we don't want to couple a higher level module with the complicated details of a low-level module.
Thus we have a general technique to at once hide complex details within modules, and elegantly handle the integration between high and low level modules -- a general solution for a vast array of problems.
Conclusion
If you are developing software that ...
- Uses some kind of persistence technology
- You plan to maintain for longer than a month or two
- You plan to make lots of changes to over time
... then I recommend you consider using this pattern, or select another solution that will make your code simpler.
Maybe not everyone will agree with the use of this pattern. That is okay. In fact, I would love to receive feedback and other ideas -- leave a comment!
The crucial goal of this blog post is for software engineers to become aware of the PROBLEM itself: the coupling between domain and persistence logic. It's prevalent. It's a problem almost any web service is susceptible to. We shouldn't have to debate whether or not it exists.
Hold the problem you are solving tightly, hold the customers tightly, and hold the solution you're building loosely [Seibel]
This quote was in relationship to product MVPs, but it applies here too. Focus on the problem. Understand it deeply. Then, decompose it into sub-problems. Encapsulate the sub-problems. Re-compose into a solution. Repeat, iteratively, until you have found a simple solution that works.
Resources
[Fowler - 2019] Martin Fowler, "Is High Quality Software Worth the Cost?" - https://martinfowler.com/articles/is-quality-worth-cost.html
[Winters, et al] Titus Winters, Tom Manshreck, Hyrum Wright, "Software Engineering at Google: Lessons Learned from Programming Over Time"
[Hickey] Rich Hickey, "Simple Made Easy" - https://www.infoq.com/presentations/Simple-Made-Easy/
[Wikipedia - MA] "Multitier Architecture" - https://en.wikipedia.org/wiki/Multitier_architecture
[Parnas] David L. Parnas, "On the Criteria To Be Used in Decomposing Systems into Modules" - https://www.win.tue.nl/~wstomv/edu/2ip30/references/criteria_for_modularization.pdf
[Fowler - 2003] Martin Fowler "AnemicDomainModel" - https://www.martinfowler.com/bliki/AnemicDomainModel.html 25 November 2003
[Cockburn] Alistair Cockburn, "Hexagonal Architecture" - https://alistair.cockburn.us/hexagonal-architecture/
[Seibel] Michael Seibel, "How to Plan an MVP" - https://youtu.be/1hHMwLxN6EM 01 August 2019 (Quote starts around 3:25)